Speeding up a huge multi-tenant SaaS database
 by Alex Yumashev ·
Updated Jun 29 2021
by Alex Yumashev ·
Updated Jun 29 2021
Here's a little story of how we sped up our SaaS backend with a one-liner magic silver bullet
The problem
Our SaaS is powered by a huge multi terabyte "multi tenant" relational database cluster. Some tables are more than 200 GB - this is crazy, to be honest. And for the multi-tenant architecture we use the dumbest possible model - "Pool" - this is when a "tenant_id" column is added to all database tables. The model is not the most effective, but super easy to implement, backup and maintain.
by the way, AWS has published a very cool doc about designing multi-tenant SaaS systems, that goes through all the options, a must-read for every CTO
Everything was slow and sluggish. Clients were furious, servers were overheating. Things like "get a record by ID" worked just fine, but getting any list, like, "unread messages for today" in a multi-terabyte database becomes a nightmare. Even with all the correct indexes. What's even worse, a fat client with a bazillion records slows down smaller customers with less data. Something needed to be done.
The Great Revelation
...And that's when we had the Great Revelation [sarcasm], which sooner or later comes to any DBA - most of the work uses the "tip" of the data. And the huge "long tail" archive just lies around as useless dead weight and used for reports only.
Our first thought was to set up "vertical" partitioning. Push the "old" data somewhere beyond the horizon (onto a separate disk or even another server), but keep the "recent" data somewhere close.
Yes, but not really.
Partitioning is hard. It turned out difficult to set up, PITA to maintain and it never works the first time. To paraphrase the well-known yachting proverb: the two happiest days in a DBA life are the day he sets up partitioning and the day he gets rid of it. Because the server still performs cross-partition scans, and those cases are pretty hard to investigate.
I can hear the audience shouting: "sharding!", "ClickHouse!", "separate OLTP from DWH!"... And similar overengineering stuff. Sorry, but no. We have a self-hosted version that should install itself with one click, even for non tech savvy customers. The less moving parts the better.
I wanted a simple hack that would solve all problems.
Meet Filtered Indexes
That's when I accidentally remembered the awesome cheat code - "filtered indexes".
Here's the thing: a database index is always built over the entire table by default. But what if we could index just the 0.1% of the data?
See, inside any CRUD application code - in the business logic - there is always a condition that distinguishes "old" data from the "new". Something like "project status = finished". Or "order status = processed", etc. And this condition is already present in most of your SELECTs. In our case, it was "ticket status = closed".
What does a junior DBA engineer do? They create an index over this column. So that the search for "unclosed tickets" or "unprocessed messages" is fast and cool.
CREATE INDEX myIndex ON messages (processed)
What does a senior DBA do? Creates a "filtered index" with this condition:
CREATE INDEX myIndex ON messages (column1, column2 ...) WHERE processed = 0 --like this
And then makes sure that this condition is in all your WHERE queries.
As a result, even in a huge multi-terabyte database we now have a small fast index of only tens of megabytes (!), which always points to the most recent data. As soon as the data ceases to satisfy the condition, it just flies away from the index. Magically.
When we built our first filtered index and started looking at the usage statistics, our jaws were on the floor - SQL Server dropped what is was doing and started eating the index like crazy. The application has accelerated significantly, the CPU load has dropped by 80%. Just look at the graph - this is before and after implementing just ONE test index.
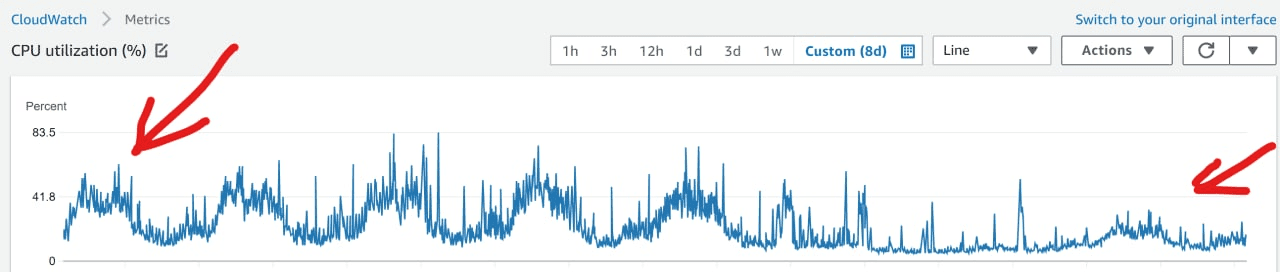
Our database server is only 4 CPU cores and 32 GB of memory, but it easily pulls off a several terabyte database with hundreds of thousands of DAU. We now have an unspoken challenge in our team - for how long we can keep using this hardware without upgrades? So far we have been stretching for years 😉
I guess the point is - before searching for bulky overengeneering solutions look at what the old, boring and unsexy RDBMS have to offer: they can do a lot of cool things even on outdated hardware.
P.S. "Filtered / partial indexed" are available in SQL Server (2008 and beyond), Postgres (7.2 and beyond), Mongo and even SQLite. MySQL is out, but there's a workaround.
P.P.S. there is a catch, however. When creating a filtered index, be sure to list the filtered column in the "include" directive. This way we force the database server to maintain "statistics" over the column. Without the statistics the index will not work, the server will just not use it.
CREATE INDEX myIndex ON Messages (Column1, Column2 ...) INCLUDE (Processed) -- important WHERE Processed = 0
Brent Ozar has more to say on this