You're backing up for the wrong disaster
 by Alex Yumashev ·
Updated May 2 2022
by Alex Yumashev ·
Updated May 2 2022
Everyone should be doing backups, right?
Coming up with a backup strategy can be complicated. Not only it can be terabytes of data. It can also be highly heterogeneous - meaning it's not just files and folders, but also databases, transaction logs, key-value stores, full-text search indexes, cloud-storage...
But that's not the biggest problem. The biggest mistake I've seen people make is - protecting themselves from the wrong disaster.
Ask yourself: What is that "data loss" you're protecting yourself from?
When someone says "data loss" engineers usually picture this:

Or this

Or, at least, this:

While in real life it's usually this:
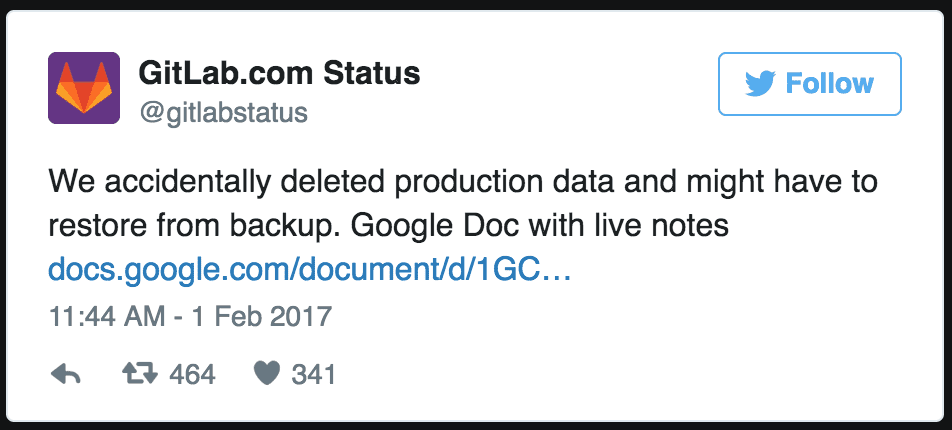
We subconsciously focus on the "movie-like" threats, like an evil hacker bringing down a server from their dark basement. Hijacking and then deleting important data by using some secret NSA/CIA backdoor in the operating system. Or at least an earthquake destroying your datacenter.
While in real life it's probably something much more prosaic: untested code, a tired sysadmin, a user deleting their own files, a developer pushing code to the wrong branch, an angry ex-employee deleting stuff after being let go...
We've been running a SaaS helpdesk app for almost 10 years and we had our share of data losses. While no data was actually lost forever (we managed to recover every time), our humble stats goes like this:
- 3.3% - hardware failures (including hard drive damage)
- 1.6% - power failures
- 6% - software failures, bugs and data corruption
- 50% - accidental deletion by a user
- 33% - accidental deletion by our own engineers
Those #4 and #5 are the ones you should prepare yourself for. These are going to be your biggest threat. Not a hurricane, not an earthquake, not a hardware failure and not a hacker attack. And one of the most popular requests from customers is going to be "help, I just deleted something". Meaning, most of the time your "restore" procedure is not actually restoring lost data, but rolling it back to a previous state (while keeping some of it "recent").
Now, I'm not saying you shouldn't protect yourself from viruses, attacks, shouldn't patch your servers or encrypt the data. I'm just saying your backup/restore procedure should be designed accordingly. Your data will probably be deleted by legit users in a legit workflow, and most backup/restore strategies are not ready for this.
Like, here's a phrase I've heard countless times:
"I don't need to backup Amazon S3 because Amazon S3 is like 99.99999-something durable"
Yeah, right. And because your users never delete anything by accident. And your developers make zero mistakes when writing code.
What makes these restores so difficult?
"So a user just deleted something, why? Just hit the restore button and relax".
The problem is when an incident happens - even a major incident - the app does not just go down and freeze in time until you "restore" it. The app keeps working. New data is being generated. Which makes restoring more complex than just "restoring from a backup" - you have to "merge" the restored data with the more recent updates.
You can't just "roll back to a yesterday's snapshot". You also have to carefully unfold and re-apply everything that's happened after.
And what about a user deleting some of their data? You can't just roll everything back 24 hours, you have to restore the lost data only, just for this one user. Oh, and there's also the "multi-tenant" case.
Which brings us to my next point...
90% of all data losses are partial
Partial restores are complicated. You have to spawn an extra "staging" environment on the side, restore tha data, then carefully transfer the lost parts from that "staging" database instance to the production one.
And this often involves writing custom scripts or even copying the data manually, reconstructing data-consistency in the process: regenerating and re-mapping ID's, rebuilding indexes, foreign keys, even rewriting parts of your application code in some cases.
Most backup/restore strategies are not ready for partial restores. Go check yours.