Product Update: Using AI to Hide Email Signatures
 by Max Al Farakh ·
Updated Sep 9 2019
by Max Al Farakh ·
Updated Sep 9 2019
We hate email signatures. There, I said it. We are sick and tired of constantly scrolling through huge disclaimers, logo images and fancy titles trying to find useful information in a wall of text. It gets even worse when an email thread or a support ticket contains multiple replies, and you need to scroll through numerous screens back and forth.
Aren't you tired of getting messages like this?
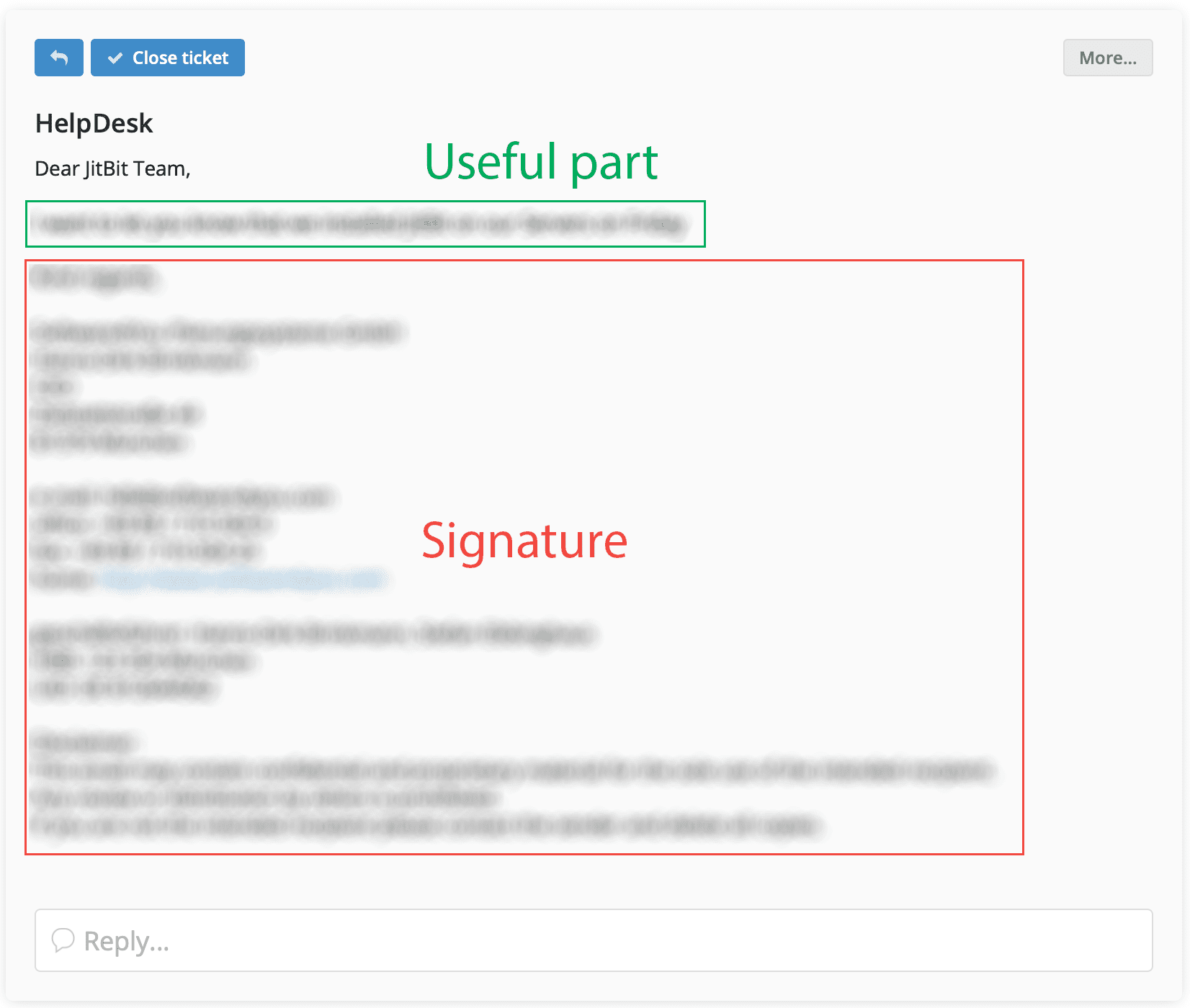
Well, we are happy to announce that from now on the SaaS version of Jitbit Helpdesk hides email signatures automatically, both within ticket body and the ticket replies. So the above message now looks like this:
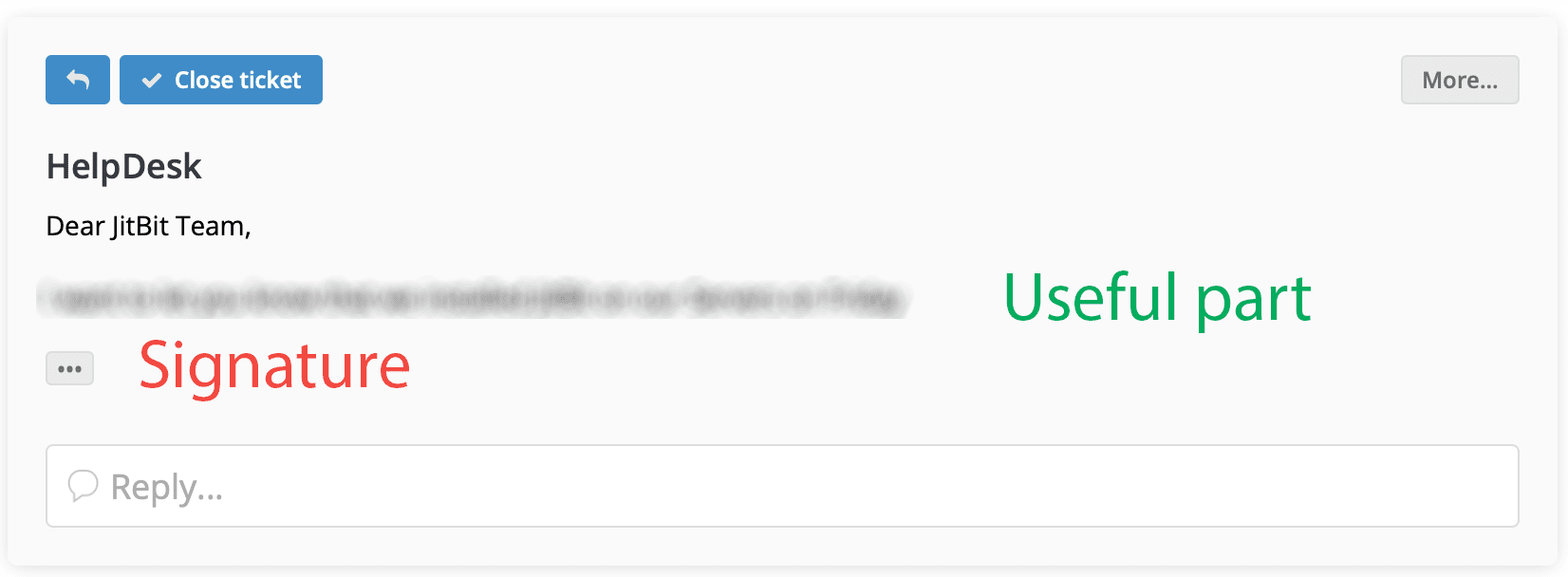
You can always click the "..." button next to the ticket body and read the signature if you absolutely need to. Otherwise your ticket feed contains only useful information now. Hopefully, your helpdesk became much more readable, and it will save you some time.
Below I will provide some quick, high-level overview of how we did this, but you don't have to read it if you don't want to. It's quite nerdy.
Actually useful AI
"AI" has been the biggest hype word this year. We started playing around with it back in April. However, we struggled to find a way to use AI technologies in a way that will actually help you be more productive.
First, we've created the "Knowledge Base suggestion bot". It isn't perfect, to say the least. It kind of works most of the time, but it wasn't something that added much value to the product. It sure does look pretty cool on marketing screenshots, but we wanted to do something real - something that will help you be more productive.
Side note: The KB bot will become much better soon. We have some plans to make it actually useful.
So, we started thinking about things that annoy us the most. After looking through a couple of tickets, the answer was clear - email signatures. The problem is - signatures are often longer than the actual useful text. They contain URLs, phone numbers, addresses, confidentiality disclaimers, "save the environment" stuff and, my favorite, inspirational quotes. There is nothing in there that I care about, but I have to scroll through it multiple times per day.
We decided to start looking into ways to hide the signatures automatically using AI.
There are some existing solutions (although, not a lot), but they didn't work for us for various reasons. We needed to make our own solution.
Training the AI model
The way our algorithm works is relatively straightforward. We need to go over an email line by line and predict if the line is a signature or not. Once we find the first signature line, we just assume that all the lines below it are parts of the signature as well. In AI it's called binary classification. There are a lot of algorithms available, but we settled on Fast tree and SVM because it produced the best results.
The problem is computers are bad at understanding text. Before we feed a line of text to the trainer, we need to convert it to an array of numbers. The process is called featurizing and the resulting array is called a feature vector.
Currently, we use 14 different features, but we continuously tweak and reevaluate them. Some feature examples are:
- Has typical words ("regards," "thanks," etc.)
- Special characters are more than 90% of the line ("---," "*")
- A lot of uppercased words
- Number of line breaks before the current line
- Has an email, phone or URL
- Position within the email
- Etc. etc. etc. There's more cool stuff there, but Alex tells me to shut up "because competitors".
After we train our model using these features, it will "know" what is most likely to be a signature. There was only one problem.
To train the model we actually needed some training data. So we took around 5000 real world emails and manually annotated signatures in those. Then we took the annotated emails and fed them to the featurizer and then to the model trainer.
The resulting model predicts signatures with almost 99% accuracy which is really good in the AI world.
Privacy note: all the model data is anonymous and contains no personally identifiable information. It's all just a bunch of numbers.
False positives and other possible issues
Customers: please report all the tickets where the signature was identified incorrectly or was not identified at all. We will work through them and retrain our model.
Non-English languages theoretically will have more false positives since 90% of the training data was in English. That said, most of the features we use are not language dependent. At least it should work the same for all the European languages (insert Brexit joke here).
We may turn it off and on again (tm) while we apply the finishing tweaks.