SaaS helpdesk outage post mortem
 by Alex Yumashev ·
Updated Sep 18 2023
by Alex Yumashev ·
Updated Sep 18 2023
On September 12, 2023 we experienced a 44 minute outage. The helpdesk app (the SaaS version) was down.
In 15 years we've never had an outage this long. Here's what's happened:
At 9:30 UTC I was outside for a morning run when my smartwatch suddenly vibrated. "Oh nice, another kilometer passed" I thought, ready to reward myself with an extra donut later.
But it wasn't a fitness achievement celebration. It was a monitoring alert from our homegrown service, that sends a push-notification to everyone when the app's error rate goes above the threshold. The errors were mostly cryptic and non-actionable: The timeout period elapsed while attempting to consume the pre-login handshake acknowledgement coming from the biggest database server in the cluster. I bolted back home after quickly checking Slack to ensure my team was in full panic mode (they were).
5 minutes later another alert popped up: "the app is down". Well, dang it, I needed to hurry up.
By the time I returned to my desk the DB server was completely dead. The team has already recycled everything they could via AWS panel, but still couldn't ssh into the machine. We decided to pull the plug on the web app (replacing it with a static page that read "app down, ETA 15 minutes, check the status page blah blah" at the load balancer) - just to make the backend stop bombarding our databases with connection attempts.
After some more incantations through the AWS control panel, we finally managed to coax the server back to life, connect via ssh and discover the root drive is out of space (was it because of the error logs?). Even after we expanded the cloud-drive (which took a while because sudo growpart requires at least some space in /tmp), mssql decided it was too cool to join the party. After re-launching the crashing service via systemctl it lasted about 5 seconds before collapsing again.
We ventured into the depths of /var/opt/mssql/logs (which seemed to be breeding like rabbits) and finally stumbled upon this gem:
Corruption detected in persistent registry: \SystemRoot\lcid.hiv
The good news? We now knew the culprit. Some files got corrupted, well, let's "uncorrupt" them. The bad news? Googling that error message gave us exactly one (one!) result:
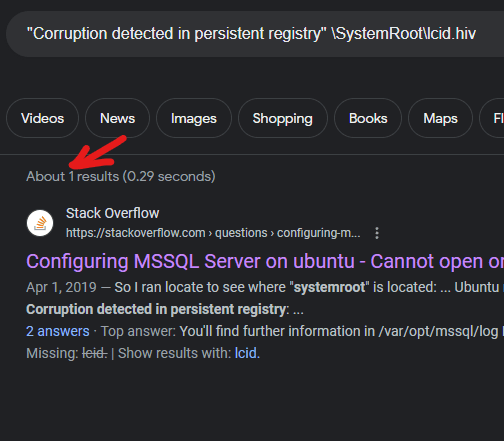
In a nutshell, we deleted the corrupted file, then re-installed the mssql-update via apt-get hoping it would restore the files. And it did - the service was up and running again. But we had to repeat the procedure five times, b/c a different file was found "corrupted" after each try.
Now, we're still in the midst of a wild investigation. We're not sure if it was the errors that triggered the log-flood, which then filled all our disk space, leading to the file corruption when we gave the server a kick using the AWS console. Or was it the file corruption that set off the error explosion, which, in turn, caused the error-flood and filled the disk space? Oh, maybe it was something completely different.
Mitigation
We've now modified our monitoring service to make sure it gives us an early heads-up next time. We've tweaked our "disk full" alerts to trigger earlier too. Lastly, we decided to upgrade the DB-servers to EC2 instance-types that come with "ephemeral" storage, and move tempdb databases to it. Since further investigation revealed that, most likely, it was the temporary database that could fill the free space rapidly even if you hard-limit the size of it in the settings! Which sets off the error flood, which fills the space even faster. This will also help make the app faster overall, since all the temporary data heavy lifting (when building reports for example) will be carried on a local SSD drive.